在当今数据驱动的时代,构建一个实时的个性化推荐系统已成为众多互联网企业的核心需求。它能极大地提升用户体验、增强用户粘性并驱动业务增长。本文旨在提供一个清晰的路线图,阐述如何从零开始,系统地设计和开发一个具备实时推荐能力的个性化系统。
一、 核心架构与设计原则
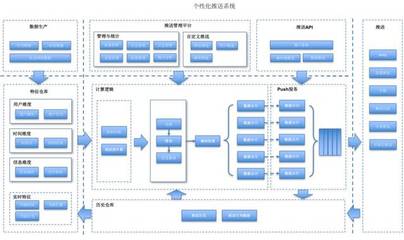
一个典型的实时个性化推荐系统通常采用分层架构,以确保模块化、可扩展性和高性能。
- 数据层:这是系统的基石。需要整合多源数据,包括:
- 用户数据:用户画像(人口统计、兴趣标签)、实时行为(点击、浏览、搜索、购买)。
- 物品数据:商品/内容属性、类别、标签。
- 上下文数据:时间、地理位置、设备信息。
- 数据通常存储在数据湖(如HDFS)或数据仓库中,同时需要实时数据流(如Kafka)来捕获用户即时行为。
- 计算层:这是系统的“大脑”,负责生成推荐。通常分为两部分:
- 离线/近线计算:处理海量历史数据,训练复杂的机器学习模型(如矩阵分解、深度神经网络),生成用户长期兴趣模型和物品关联关系。这个过程通常在分布式计算框架(如Spark、Flink)上周期性地运行。
- 在线实时计算:这是“实时”特性的核心。它负责:
- 实时处理用户行为流,更新用户的短期兴趣向量(例如,使用Flink进行流处理)。
- 结合离线模型输出的用户长期兴趣和实时更新的短期兴趣,进行毫秒级的推荐结果召回与排序。
- 在线排序(Ranking)模型(如逻辑回归、GBDT、深度学习模型)负责对召回的大量候选物品进行精排,综合得分最高者呈现给用户。
- 服务层:作为系统的对外接口,提供高并发、低延迟的推荐服务。通常是一个RESTful API或gRPC服务,负责:
- 接收前端请求(包含用户ID、上下文)。
- 调用计算层(特别是在线部分)获取推荐列表。
- 应用业务规则(如过滤已购商品、推广位插槽)进行最终调整。
- 记录推荐日志,用于后续的效果评估和模型迭代。
- 存储层:为不同需求提供高速存取。
- 特征存储:存储用户和物品的实时/离线特征向量,通常使用Redis或内存数据库,以保证毫秒级读取。
- 模型存储:存储训练好的离线模型文件,供在线服务加载。
- 结果缓存:对热门或通用的推荐结果进行缓存(如使用Redis),减轻计算压力。
核心设计原则:解耦、可扩展、容错、可观测(完善的监控和日志体系)。
二、 关键开发步骤
- 需求分析与目标定义:明确业务目标(提升点击率、转化率、停留时长?),确定评测指标(准确率、召回率、AUC、线上A/B测试指标)。
- 数据管道搭建:
- 建立批量数据管道,将历史数据导入数据仓库。
- 建立实时数据管道,使用Kafka等消息队列收集用户行为事件,并利用Flink/Spark Streaming进行实时处理与特征工程。
- 召回策略开发:实现多种召回通道,以平衡多样性和相关性。
- 协同过滤:基于用户或物品的相似度。
- 基于内容:根据用户历史喜欢的物品属性推荐相似物品。
- 热门/趋势:作为冷启动和多样性补充。
- 向量召回:使用双塔模型等深度学习模型,将用户和物品映射到同一向量空间,通过近似最近邻搜索(如Faiss)快速召回。
- 排序模型开发与迭代:
- 初期:可采用逻辑回归(LR)等简单模型,快速上线验证流程。
- 中期:引入特征交叉,使用因子分解机(FM)、梯度提升决策树(GBDT)。
- 成熟期:部署深度学习模型(如DeepFM、Wide & Deep、DIN),更好地建模复杂非线性关系和用户兴趣动态变化。
- 模型训练需使用离线日志数据,并持续进行线上A/B测试优化。
- 实时反馈闭环:这是实现“实时个性化”的关键。设计流处理作业,实时解析用户对推荐结果的反馈(点击/忽略),立即更新用户的实时兴趣特征,并可能触发对下一次请求的推荐结果的即时调整。
- 服务部署与运维:
- 使用微服务架构部署推荐服务。
- 实现特征、模型、服务的分离部署与独立更新。
- 建立完善的监控告警系统,监控QPS、延迟、错误率及业务指标波动。
三、 技术栈选型建议
- 数据流:Apache Kafka, Apache Pulsar
- 流处理:Apache Flink(首选,状态计算能力强),Apache Spark Streaming
- 离线计算:Apache Spark
- 特征/模型存储:Redis, Memcached, Cassandra
- 向量检索:Facebook Faiss, Spotify Annoy, Milvus
- 在线服务:Spring Boot (Java), Gin (Golang), 或高性能RPC框架(gRPC)
- 模型训练框架:TensorFlow, PyTorch, XGBoost/LightGBM
- 部署与编排:Docker, Kubernetes
四、 挑战与注意事项
- 冷启动问题:对于新用户或新物品,缺乏历史数据。解决方案:利用上下文信息、热门推荐、跨域信息迁移或强化学习探索。
- 数据稀疏性:用户-物品交互矩阵极其稀疏。解决方案:使用深度学习、引入更多侧信息(side information)。
- 系统延迟:实时推荐要求端到端延迟通常在100毫秒以内。需优化每一个环节,特别是特征读取和模型推理。
- 评估体系:离线指标(如AUC)与线上业务指标(如CTR)可能不一致,必须以线上A/B测试结果为准。
- 工程复杂性:系统涉及数据处理、机器学习、高并发服务等多个领域,需要跨职能团队紧密协作。
###
从零构建实时个性化推荐系统是一项复杂的系统工程,融合了大数据处理、机器学习和软件工程的精华。它没有一成不变的银弹,最佳实践是在清晰的架构指导下,采用迭代式开发,从简单可行的方案开始,通过数据反馈不断验证和优化,逐步演进成一个强大、智能的推荐引擎。核心在于建立起一个能够持续学习、快速迭代的“数据-模型-服务”闭环。